The AI-native marketing analytics startup
How will consumer services solve customer churn in an AI native world?

The AI-native marketing analytics startup
How will consumer services solve customer churn in an AI native world?

For the past decade, I’ve thought about the following question, in some variation, almost every single day: what causes users to churn from a service? Whether running a consumer subscription and desperately fighting to keep each user engaged, or running a data company that helps consumer subscriptions better understand their users and prevent them from churning, I have thought about this problem in one way or another.
For the past year, I’ve also thought about another question, in some form, almost every day: what does an AI native startup look like?
So, today, I’ll tackle the intersection of those two problems.
The status quo approach
In today’s world, Growth & Lifecycle Marketing teams generally deal with this problem as follows: IDENTIFY, ACT, MEASURE, REPEAT.
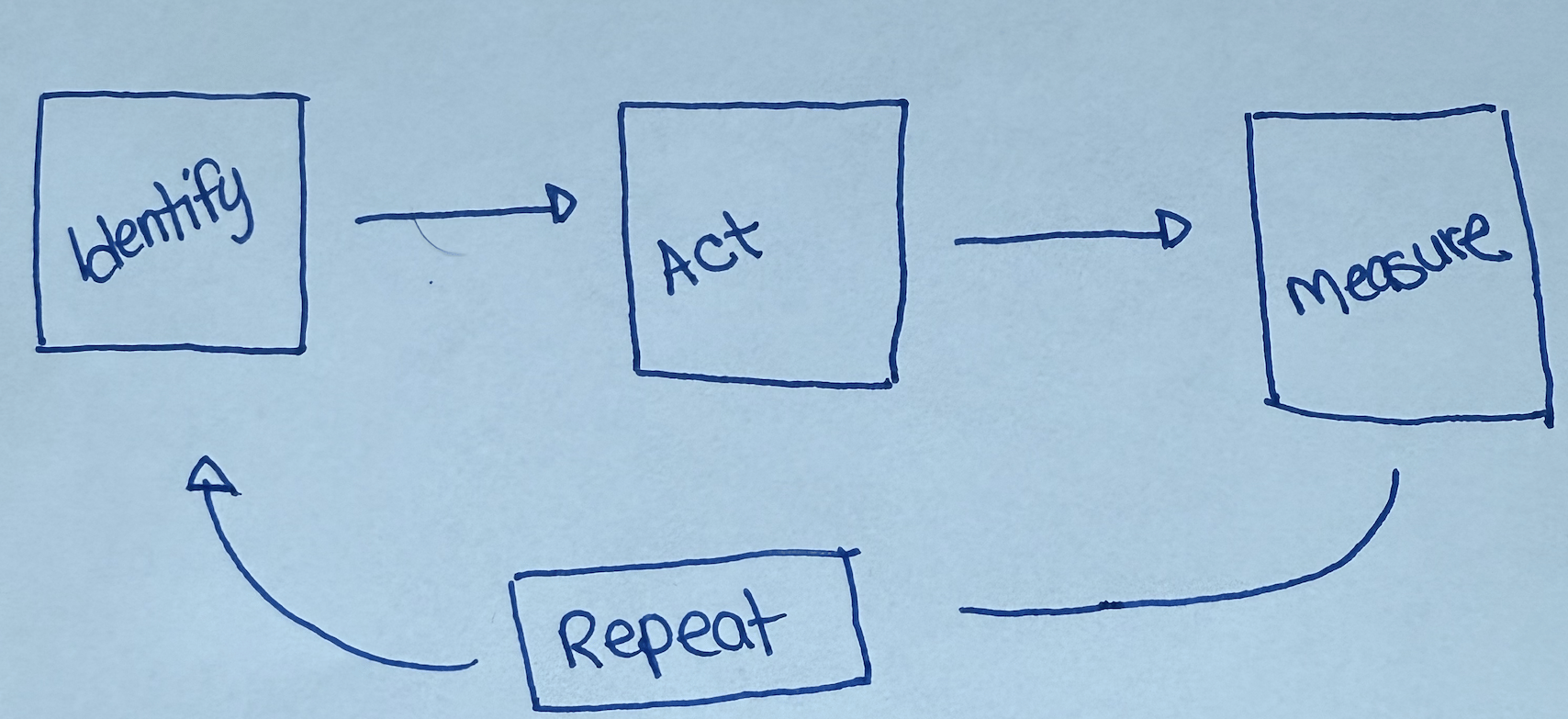
Step 1: Identify
Identify customers who are likely to churn before they do. This is primarily done by analyzing first-party usage data in the early in the subscriber’s life cycle: how they were acquired, how frequently did they engage, how long did they engage, and what did they engage with. For example, I’m sure Peloton has a model that suggests, if a user…
signed up based on a word-of-mouth referral (referral source)
uses one of their products multiple times in the first month (usage frequency)
for at least 5 hours (usage intensity)
took classes with at least 2 different instructors (content type)
and it is a hardware-related subscription (plan tier)
…they are almost definitely not going to churn in the first 3 years of subscription.
That’s a lot of confidence to gain in such a short period of time!
Occasionally, companies will incorporate third-party data into their models (e.g. demographics). Perhaps users with identical usage patterns but different demographic / socioeconomic backgrounds will have different likelihoods of future churn. But this is much less common than first-party usage data (mainly because most growth marketers would say our first-party data is good enough!)
Larger, more brand marketing focused teams, will also incorporate broad customer segmentation into this mix. That is, they will run a survey, identify similarities in behavior, and group them into buckets with cute names like “early adopters” and “laggards” (for any Geoffrey Moore fans out there) with the use of a typing tool.
All of these approaches, in sum, produce one outcome: a clear prediction on whether a user will churn based on several variables that turn out to be pretty darn predictive of whether they will churn.
Step 2: Act
Once the lifetime value of each user is estimated, execution teams will step in to improve outcomes. They will step in to ensure high-value users stay high-value; and to move low-value users into the high-value bucket.
Their job is to ensure as many users as possible take the behaviors that are associated with high-value users. For example, onboarding successfully, consuming a certain type of product / content experience, logging in a certain number of times, or giving incentives for unengaged users to give it a second chance.
They do this via all of the possible intervention channels at their disposal. For example, in-product notifications, emails & text messages, and paid retargeting ads.
These teams work in coordination with the aforementioned customer segmentation. Different customer segments respond best to different behaviors (e.g. high HHI users are not nearly as likely to respond well to price incentives).
As you can imagine, this gets pretty multidimensional. Execution teams are…
Coordinating different behavioral triggers
To a variety of different customer segments
At different times in each customer’s journey
Across a variety of different channels
And each message is iterated upon to get the perfect creative & copy
… at least it seems complicated in a human-centric world.
Step 3: Measure
OK, we identified high and low-value users. We grouped them into a matrix of customer segments. We tried to take actions to improve low-value users into high-value users. Did it work? After each round of intervention (really, it’s a continuous feedback loop), another team will feed data back on whether these behavioral interventions worked. The questions are relatively straightforward: were the customer segments behaving in expected ways? Did the interventions work? If so, which ones, and how much?
The higher leverage work that the data & analytics teams do is upstream: setting up data pipelines to ensure they can capture the entire user journey from start (where was this user acquired, for how much, by which ad, etc) to finish (they churned, why did they churn, and hopefully why were they won back). Because there are dozens of third-party advertising, marketing, and software platforms in the mix, doing this in a uniform way often gets complicated.
Step #4: Repeat
‘nuff said!
Key problems with this approach
Lossy & time-consuming. Lots of people doing a process in waterfall methodology is inherently limiting.
Reactive. You have to wait for the user to sign up and use your product before you get a signal. Learning that you acquired a not-so-great user is a huge price to pay after you’ve already expended all of the time & energy to acquire them.
One-dimensional. It attempts to categorize different user journeys into a series of aggregate groups not because those users are the same but because it is computationally impossible for the human mind to personalize approaches across thousands of unique individuals.
Expensive. I just described a large group of people tasked with doing this work. There are typically teams associated with each step of the current workflow. The marketing analytics team may identify, and ask the lifecycle marketing team to act, while the data engineering team may set up the infrastructure allowing for measure. Often, this is multiplied for each channel of reengagement: for example, there are multiple lifecycle marketing teams that act across email, product notifications, and other marketing campaigns.
The future approach: hey Siri, solve churn
The promise of agentic AI is not only that you can trigger a single part of this workflow (“create a push notification that offers a discount to users”) but rather that you can trigger the entire workflow (“improve my churn problem”).
There’s been a lot written about how to build an agentic AI system – that’s not really the point of this post – so, for today, let’s assume it’s possible: that you can stitch together a solution that breaks this workflow down into its component parts and writes software to automate each & every one of them.
Instead, let’s focus on what the humans can do to make this workflow effective. Here’s the key thing to know: the workflow isn’t the interesting part, the context it’s injected with is.
Identify why users churn
Why do your users churn? Most marketing teams have strong structured, first-party data signals on this (like those mentioned at the top of this article). But most are underweight in two key areas that could be utilized much more effectively in an AI future.
Third-party data: A lot of your users’ decision to sign up for your service has little to do with your service, per se. For example, maybe they had a major life event (moved, new job, had a child), macroeconomic factors changed (recession), new technology was released (new folding phones), viral trends (TikTok influencers going crazy about a product category), and so on.
Unstructured data: Think about your own journey to form a relationship with any of the products you now love. Let’s go back to Peloton. Perhaps you tried the service at your friend’s house; you saw dozens of influencer videos on Instagram; you saw several paid ads; and the next holiday season your significant other purchased it for you. And then, because your family made a new years’ resolution to be healthier, you began to use it on a daily basis. In a marketer’s database, you are recorded as
status: new_useracquisition_channel: google_adscampaign: holiday_promotioncreative: holidaypromo2025_2_abcsegment: new_years_resolutions
Think about how much richer your actual journey is than the above database entry. If the marketer knew you had tried it at your friend’s house, they’d be able to target you much more effectively than the creepy “I searched for a product and now my social media feed is exclusively ads of that product” approach. Maybe they’d even give your friend a referral code to pass along to you! Maybe they’d recommend organic influencer content to ensure you could pursue your goals with ease. But, unless you’re part of the lucky 1% of users they survey each year, all of that information is likely abstracted away into a few bits of structured data.
Often, customer segmentation analyses are bound by human cognition. Sure, there may be a way to create 100 new customer segments out of any single customer segment but is the juice worth the squeeze? That adds a ton of complexity for a human — and how much lift does it create? That’s no longer a problem in an agentic workflow. Each customer segment – and the remedies to treat – can be multiplied many times over.
Collect every single data point you can
So the game for us humans shifts from executing the workflow to seeding it with as many datapoints as possible, including data that was previously not collectable nor structurable and, thus, ignored. All of those creative juices of growth marketing teams need to be rerouted towards thinking about creative ways to capture that data. The opportunities are seemingly endless.
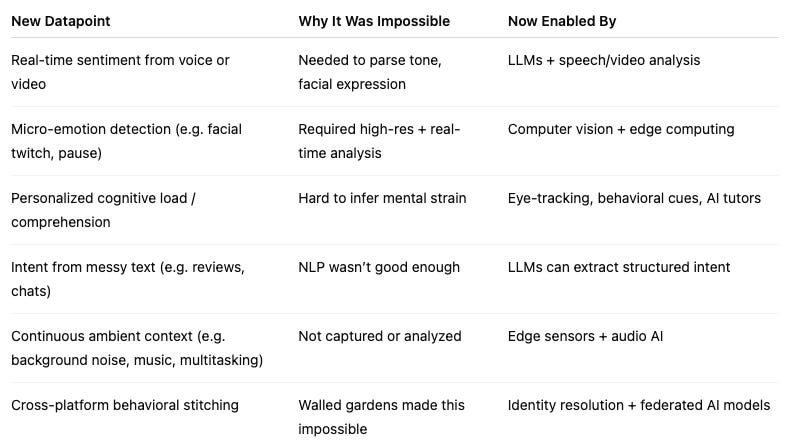
For example, maybe the following things become even more important:
Running micro-surveys of users to collect attitudinal data
Tracking product usage, even of physical products
Collecting third-party data about your users’ usage of other products
Rather than interpreting these signals, our job will shift to figuring out how to collect them, and passing them along. With the twin constraints lifted of the data no longer needs to be structured nor interpretable by humans, I’m betting there's a lot of data out there just waiting to be collected.
Ultimately, this looks like the most detailed user graph the world has ever seen.
Where will this work best
I’ve spoken with dozens of growth marketers about this concept, at a high level. Most of them react in the same way: Rameez, our ability to predict churn is good enough right now. We’re not looking to invest more to improve it. We love the idea that we could predict earlier or that we could use third-party data to predict better but it's already an “A” and we have bigger problems.
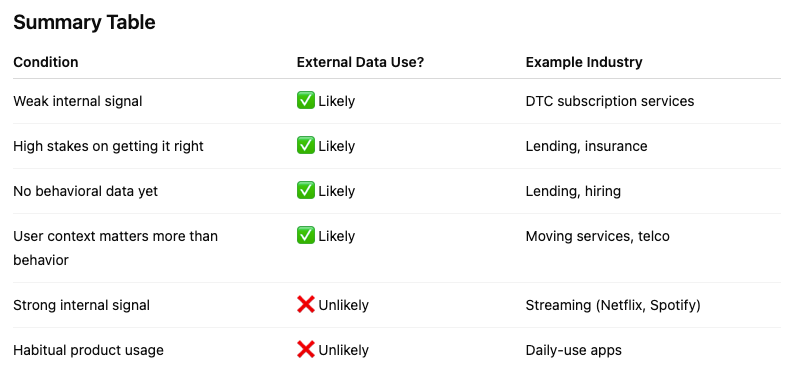
Fair point. So where is this approach most likely to see massive adoption? Where first party data solutions aren’t yet good enough. There are a couple criteria that must be met:
Infrequent usage makes churn unpredictable since there is no immediate data (e.g. visiting the doctor’s office)
The service is not sold direct-to-consumer but, rather, through retail channels so the data availability is low.
This can also apply to offline goods. Without the ability to track a user’s behavior, it’s impossible to use the usage-based churn models described above.
The cost of any missed prediction is high. This applies to extremely high LTV categories. If you are going to have a customer for 50 years, and they’re paying you $1,000 a year, the cost of losing any single customer is crushing.
Predictive power has less to do with usage than other things. For example, a move to a non-Spectrum covered territory has a lot more to do with churn than usage.
“Implementation details”
The future org chart
What will the org chart look like once the IDENTIFY ACT MEASURE REPEAT is a black box?
(Duh) AI Agents: Tomasz Tunguz recently posted about The Rise of the Agent Manager. This sums it up well. You have a Head of Growth (agent) who gives their team a task: identify churn predictive variables, do things that reverse the decision to churn once you identify them, measure whether they worked, repeat.

This elevates humans to think creatively about all the new signals they can capture and work to collect them. Stellar data engineering teams will shine.
And, it goes without saying, all of this is a marketing workflow that depends on an incredible product. The creativity of building a product that gets product/market fit with a certain customer segment is the closest thing to an artist I’ll ever be – so I’m biased – but I definitely consider it to be art. Therefore, it’ll be the last thing we outsource to AI.
The future revenue model
The V1 revenue model will be anchored around cost savings (“hey, we can perform this marketing workflow as well as your team of many humans”) but the much more consequential V2 revenue model will be based around outcomes (“we’ll do this workflow so well that we just want to collect a % of the improvements we create”).
One of software’s iconic founder / executives, Bret Taylor, with his new company Sierra.ai, has championed outcomes-based pricing. As Sierra puts it, “outcome-based pricing is tied to tangible business impacts—such as a resolved support conversation, a saved cancellation, an upsell, a cross-sell, or any number of valuable outcomes. If the conversation is unresolved, in most cases, there's no charge.”

With the shift in outcome-based pricing, will come a shift to emphasize professional services. Because they are so closely aligned with their client, the software vendor must ensure the client is onboarded successfully, which means that the software vendor will spend as much time thinking about how to identify & collect new forms of data to feed the AI model as the client will.
Back in 2015, when I had my first experience with Looker’s forward deployed engineering model, I remember thinking “wow, this is the future.” Well, I was either wrong or just 10 years too early — but it didn’t catch on en masse.

In combination, here’s what we’re left with: an outcomes-based revenue model, which will create better alignment between vendor & client, allowing for fewer resources to be spent manually executing workflows, and more human creativity to be channeled to even higher leverage activities. Hard to be pessimistic about that!